Though there are advancements in speaker recognition technology, available systems often fail to correctly recognize speakers especially in noisy environments. The use of Mel-frequency cepstral coefficients (MFCC) has been improved using Convolutional Neural Networks (CNN) yet difficulties in achieving high accuracies still exists. Hybrid algorithms combining MFCC and Region-based Convolutional Neural Networks (RCNN) have been found to be promising. In this research features from speech signals were extracted for speaker recognition, to denoise the signals, design and develop a DFT-based denoising system using spectrum subtraction and to develop a speaker recognition method for the Verbatim Transcription using MFCC. The DFT was used to transform the sampled audio signal waveform into a frequency-domain signal. RCNN was used to model the characteristics of speakers based on their voice samples, and to classify them into different categories or identities. The novelty of the research was that it used MFCC integrated with RCNN and optimized with Host-Cuckoo Optimization (HCO) algorithm. HCO algorithm is capable of further weight optimization through the process of generating fit cuckoos for best weights. It also captured the temporal dependencies and long-term information. The system was tested and validated on audio recordings from different personalities from the National Assembly of Kenya. The results were compared with the actual identity of the speakers to confirm accuracy. The performance of the proposed approach was compared with two other existing speaker recognition the traditional approaches being MFCC-CNN and Linear Predictive Coefficients (LPC)-CNN. The comparison was based the Equal Error Rate (EER), False Rejection Rate (FRR), False Match Rate (FMR), and True Match Rate (TMR). Results show that the proposed algorithm outperformed the others in maintaining a lowest EER, FMR, FRR and highest TMR.
| Published in | International Journal of Intelligent Information Systems (Volume 13, Issue 5) |
| DOI | 10.11648/j.ijiis.20241305.11 |
| Page(s) | 94-108 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Speaker Recognition, Verbatim Transcription, Spectrum Subtraction, Mel-Frequency Cepstral Coefficients (MFCC), Linear Predictive Cepstral Coefficients, HCO Algorithm
SNR | Signal-to-Noise Ratio |
FFT | Fast Fourier Transform |
MFCC | Mel-Frequency Cepstral Coefficient |
DC | Direct Current |
DFT | Discrete Fourier Transform |
R-CNN/RCNN | Region-based Convolutional Neural Network |
HCO | Host-Cuckoo Optimization |
CNN | Convolutional Neural Network |
RNN | Recursive Neural Network |
SVM | Support Vector Machine |
EER | Equal Error Rate |
FMR | False Match Rate |
FRR | False Rejection Rate |
TMR | True Match Rate |
LDA | Linear Discriminant Analysis |
PCA | Principal Component Analysis |
GMM | Gaussian Mixture Models |
HMM | Hidden Markov Models |
LPC | Linear Predictive Coefficients |
CMS | Cepstral Mean Subtraction |
CMVN | Cepstral Mean and Variance Normalization |
RASTA | Relative Spectral Transform Analysis |
| [1] | R. M. Hanifa, K. Isa, and S. Mohamad, “A review on speaker recognition: Technology and challenges,” Comput. Electr. Eng., vol. 90, p. 107005, 2021. |
| [2] | M. Jakubec, E. Lieskovska, and R. Jarina, “An Overview of Automatic Speaker Recognition in Adverse Acoustic Environment,” presented at the 2020 18th International Conference on Emerging eLearning Technologies and Applications (ICETA), IEEE, 2020, pp. 211–218. |
| [3] | D. Hershcovich et al., “Challenges and strategies in cross-cultural NLP,” ArXiv Prepr. ArXiv220310020, 2022. |
| [4] | V. N. Ngoni, “English–Bukusu Automatic Machine Translation for Digital Services Inclusion in E-governance,” 2022. |
| [5] | N. O. Ogechi, “On language rights in Kenya,” Nord. J. Afr. Stud., vol. 12, no. 3, pp. 19–19, 2003. |
| [6] | S. S. Tirumala, S. R. Shahamiri, A. S. Garhwal, and R. Wang, “Speaker identification features extraction methods: A systematic review,” Expert Syst. Appl., vol. 90, pp. 250–271, 2017. |
| [7] | National Assembly of Kenya, “Standing Orders.” National Assembly of Kenya, 2013. [Online]. Available: |
| [8] | R. Jahangir et al., “Text-independent speaker identification through feature fusion and deep neural network,” IEEE Access, vol. 8, pp. 32187–32202, 2020. |
| [9] | G. Sharma, K. Umapathy, and S. Krishnan, “Trends in audio signal feature extraction methods,” Appl. Acoust., vol. 158, p. 107020, 2020. |
| [10] | J. V. E. López, “Adaptation of Speaker and Speech Recognition Methods for theAutomatic Screening of Speech Disorders Using Machine Learning,” 2023. |
| [11] | M. M. Kabir, M. F. Mridha, J. Shin, I. Jahan, and A. Q. Ohi, “A survey of speaker recognition: Fundamental theories, recognition methods and opportunities,” IEEE Access, vol. 9, pp. 79236–79263, 2021. |
| [12] | S. J. Jainar, P. L. Sale, and B. Nagaraja, “VAD, feature extraction and modelling techniques for speaker recognition: a review,” Int. J. Signal Imaging Syst. Eng., vol. 12, no. 1–2, pp. 1–18, 2020. |
| [13] | S. K. Sarangi and G. Saha, “Improved speech-signal based frequency warping scale for cepstral feature in robust speaker verification system,” J. Signal Process. Syst., vol. 92, pp. 679–692, 2020. |
| [14] | S. Bharadwaj and P. B. Acharjee, “Analysis of Prosodic features for the degree of emotions of an Assamese Emotional Speech,” presented at the 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), IEEE, 2020, pp. 1441–1452. |
| [15] | C. Quam and S. C. Creel, “Impacts of acoustic‐phonetic variability on perceptual development for spoken language: A review,” Wiley Interdiscip. Rev. Cogn. Sci., vol. 12, no. 5, p. e1558, 2021. |
| [16] | S. Ali, S. Tanweer, S. S. Khalid, and N. Rao, “Mel frequency cepstral coefficient: a review,” ICIDSSD, 2020. |
| [17] | S. Pangaonkar and A. Panat, “A Review of Various Techniques Related to Feature Extraction and Classification for Speech Signal Analysis,” presented at the ICDSMLA 2019: Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications, Springer, 2020, pp. 534–549. |
| [18] | B. A. Aicha and F. Kacem, “Conventional Machine Learning and Feature Engineering for Vocal Fold Precancerous Lesions Detection Using Acoustic Features,” Circuits Syst. Signal Process., pp. 1–33, 2023. |
| [19] | K. Jagadeeshwar, T. Sreenivasarao, P. Pulicherla, K. Satyanarayana, K. M. Lakshmi, and P. M. Kumar, “ASERNet: Automatic speech emotion recognition system using MFCC-based LPC approach with deep learning CNN,” Int. J. Model. Simul. Sci. Comput., vol. 14, no. 04, p. 2341029, 2023. |
| [20] | M. Ramashini, P. E. Abas, K. Mohanchandra, and L. C. De Silva, “Robust cepstral feature for bird sound classification,” Int. J. Electr. Comput. Eng., vol. 12, no. 2, p. 1477, 2022. |
| [21] | G. Vanderreydt and K. Demuynck, “A Novel Channel estimate for noise robust speech recognition,” Comput. Speech Lang., p. 101598, 2023. |
| [22] | H. Hermansky and N. Morgan, “RASTA processing of speech,” IEEE Trans. Speech Audio Process., vol. 2, no. 4, pp. 578–589, 1994. |
| [23] | N. N. Alrouqi, “Additive Noise Subtraction for Environmental Noise in Speech Recognition,” 2021. |
| [24] | S. Alharbi et al., “Automatic speech recognition: Systematic literature review,” IEEE Access, vol. 9, pp. 131858–131876, 2021. |
| [25] | Wen-Jie Song, Chen Chen, Tian-Yang Sun, and Wei Wang, “A Robust Equalization Feature for Language Recognition,” J. Inf. Sci. Eng., vol. 36, no. 3, pp. 561–576, May 2020, |
| [26] | G. Manikandan and S. Abirami, “Feature Selection Is Important: State-of-the-Art Methods and Application Domains of Feature Selection on High-Dimensional Data,” in Applications in Ubiquitous Computing, R. Kumar and S. Paiva, Eds., in EAI/Springer Innovations in Communication and Computing. Cham: Springer International Publishing, 2021, pp. 177–196. |
| [27] | O. Ghahabi, P. Safari, and J. Hernando, “Deep Learning in Speaker Recognition,” in Development and Analysis of Deep Learning Architectures, W. Pedrycz and S.-M. Chen, Eds., in Studies in Computational Intelligence, Cham: Springer International Publishing, 2020, pp. 145–169. |
| [28] | Y. Wang, L. Zheng, Y. Gao, and S. Li, “Vibration Signal Extraction Based on FFT and Least Square Method,” IEEE Access, vol. 8, pp. 224092–224107, 2020, |
| [29] | J. Agrawal, M. Gupta, and H. Garg, “A review on speech separation in cocktail party environment: challenges and approaches,” Multimed. Tools Appl., vol. 82, no. 20, pp. 31035–31067, Aug. 2023, |
| [30] | P. Golik, “Data-driven deep modeling and training for automatic speech recognition,” 2020. |
| [31] | R. Haeb-Umbach, J. Heymann, L. Drude, S. Watanabe, M. Delcroix, and T. Nakatani, “Far-Field Automatic Speech Recognition,” Proc. IEEE, vol. 109, no. 2, pp. 124–148, Feb. 2021, |
| [32] | A. Lauraitis, R. Maskeliūnas, R. Damaševičius, and T. Krilavičius, “Detection of Speech Impairments Using Cepstrum, Auditory Spectrogram and Wavelet Time Scattering Domain Features,” IEEE Access, vol. 8, pp. 96162–96172, 2020, |
| [33] | S. A. El-Moneim et al., “Speaker recognition based on pre-processing approaches,” Int. J. Speech Technol., vol. 23, no. 2, pp. 435–442, Jun. 2020, |
| [34] | N. Chen and S. Fu, “Uncertainty quantification of nonlinear Lagrangian data assimilation using linear stochastic forecast models,” Phys. Nonlinear Phenom., vol. 452, p. 133784, Oct. 2023, |
| [35] | A. P. Fellows, M. T. L. Casford, and P. B. Davies, “Spectral Analysis and Deconvolution of the Amide I Band of Proteins Presenting with High-Frequency Noise and Baseline Shifts,” Appl. Spectrosc., vol. 74, no. 5, pp. 597–615, May 2020, |
| [36] | N. Saleem, J. Gao, M. I. Khattak, H. T. Rauf, S. Kadry, and M. Shafi, “DeepResGRU: Residual gated recurrent neural network-augmented Kalman filtering for speech enhancement and recognition,” Knowl.-Based Syst., vol. 238, p. 107914, Feb. 2022, |
| [37] | P. Bansal, S. A. Imam, and R. Bharti, “Speaker recognition using MFCC, shifted MFCC with vector quantization and fuzzy,” presented at the 2015 International Conference on Soft Computing Techniques and Implementations (ICSCTI), IEEE, 2015, pp. 41–44. |
| [38] | L.-M. Dogariu, J. Benesty, C. Paleologu, and S. Ciochină, “An Insightful Overview of the Wiener Filter for System Identification,” Appl. Sci., vol. 11, no. 17, Art. no. 17, Jan. 2021, |
| [39] | Y. Zouhir, M. Zarka, and K. Ouni, “Power Normalized Gammachirp Cepstral (PNGC) coefficients-based approach for robust speaker recognition,” Appl. Acoust., vol. 205, p. 109272, Mar. 2023, |
| [40] | A. Ahmed, Y. Serrestou, K. Raoof, and J.-F. Diouris, “Empirical Mode Decomposition-Based Feature Extraction for Environmental Sound Classification,” Sensors, vol. 22, no. 20, Art. no. 20, Jan. 2022, |
| [41] | Z. Bai and X.-L. Zhang, “Speaker recognition based on deep learning: An overview,” Neural Netw., vol. 140, pp. 65–99, 2021. |
| [42] | Gaurav, S. Bhardwaj, and R. Agarwal, “An efficient speaker identification framework based on Mask R-CNN classifier parameter optimized using hosted cuckoo optimization (HCO),” J. Ambient Intell. Humaniz. Comput., vol. 14, no. 10, pp. 13613–13625, Oct. 2023, |
| [43] | Z. Touati-Hamad and M. R. Laouar, “Enhancing Education Decision-Making with Deep Learning for Arabic Spoken Digit Recognition,” p. 4321405 Bytes, 2023, |
| [44] | W.-C. Lin and C. Busso, “Chunk-Level Speech Emotion Recognition: A General Framework of Sequence-to-One Dynamic Temporal Modeling,” IEEE Trans. Affect. Comput., vol. 14, no. 2, pp. 1215–1227, Apr. 2023, |
| [45] | S. Agarwal, J. O. D. Terrail, and F. Jurie, “Recent Advances in Object Detection in the Age of Deep Convolutional Neural Networks.” arXiv, Aug. 20, 2019. |
| [46] | C. Zhang, Z. Yang, X. He, and L. Deng, “Multimodal Intelligence: Representation Learning, Information Fusion, and Applications,” IEEE J. Sel. Top. Signal Process., vol. 14, no. 3, pp. 478–493, Mar. 2020, |
| [47] | S. Hourri, N. S. Nikolov, and J. Kharroubi, “Convolutional neural network vectors for speaker recognition,” Int. J. Speech Technol., vol. 24, no. 2, pp. 389–400, Jun. 2021, |
| [48] | G. Hu, Z. Zhang, A. Armaou, and Z. Yan, “Robust extended Kalman filter based state estimation for nonlinear dynamic processes with measurements corrupted by gross errors,” J. Taiwan Inst. Chem. Eng., vol. 106, pp. 20–33, Jan. 2020, |
| [49] | O. Deshpande, K. Solanki, S. P. Suribhatla, S. Zaveri, and L. Ghodasara, “Simulating the DFT Algorithm for Audio Processing,” ArXiv Prepr. ArXiv210502820, 2021. |
| [50] | M. Awais, Md. T. Bin Iqbal, and S.-H. Bae, “Revisiting Internal Covariate Shift for Batch Normalization,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 11, pp. 5082–5092, Nov. 2021, |
| [51] | H. Moayed and E. G. Mansoori, “Improving Regularization in Deep Neural Networks by Co-adaptation Trace Detection,” Neural Process. Lett., vol. 55, no. 6, pp. 7985–7997, Dec. 2023, |
| [52] | R. Gadagkar, “How to Design Experiments in Animal Behaviour,” Resonance, vol. 25, no. 10, pp. 1419–1455, Oct. 2020, |
APA Style
Otenyi, S. N., Ngoo, L., Kiragu, H. (2024). Speaker Recognition System Using Hybrid of MFCC and RCNN with HCO Algorithm Optimization. International Journal of Intelligent Information Systems, 13(5), 94-108. https://doi.org/10.11648/j.ijiis.20241305.11
ACS Style
Otenyi, S. N.; Ngoo, L.; Kiragu, H. Speaker Recognition System Using Hybrid of MFCC and RCNN with HCO Algorithm Optimization. Int. J. Intell. Inf. Syst. 2024, 13(5), 94-108. doi: 10.11648/j.ijiis.20241305.11
AMA Style
Otenyi SN, Ngoo L, Kiragu H. Speaker Recognition System Using Hybrid of MFCC and RCNN with HCO Algorithm Optimization. Int J Intell Inf Syst. 2024;13(5):94-108. doi: 10.11648/j.ijiis.20241305.11
@article{10.11648/j.ijiis.20241305.11,
author = {Stephen Nyakuti Otenyi and Livingstone Ngoo and Henry Kiragu},
title = {Speaker Recognition System Using Hybrid of MFCC and RCNN with HCO Algorithm Optimization
},
journal = {International Journal of Intelligent Information Systems},
volume = {13},
number = {5},
pages = {94-108},
doi = {10.11648/j.ijiis.20241305.11},
url = {https://doi.org/10.11648/j.ijiis.20241305.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijiis.20241305.11},
abstract = {Though there are advancements in speaker recognition technology, available systems often fail to correctly recognize speakers especially in noisy environments. The use of Mel-frequency cepstral coefficients (MFCC) has been improved using Convolutional Neural Networks (CNN) yet difficulties in achieving high accuracies still exists. Hybrid algorithms combining MFCC and Region-based Convolutional Neural Networks (RCNN) have been found to be promising. In this research features from speech signals were extracted for speaker recognition, to denoise the signals, design and develop a DFT-based denoising system using spectrum subtraction and to develop a speaker recognition method for the Verbatim Transcription using MFCC. The DFT was used to transform the sampled audio signal waveform into a frequency-domain signal. RCNN was used to model the characteristics of speakers based on their voice samples, and to classify them into different categories or identities. The novelty of the research was that it used MFCC integrated with RCNN and optimized with Host-Cuckoo Optimization (HCO) algorithm. HCO algorithm is capable of further weight optimization through the process of generating fit cuckoos for best weights. It also captured the temporal dependencies and long-term information. The system was tested and validated on audio recordings from different personalities from the National Assembly of Kenya. The results were compared with the actual identity of the speakers to confirm accuracy. The performance of the proposed approach was compared with two other existing speaker recognition the traditional approaches being MFCC-CNN and Linear Predictive Coefficients (LPC)-CNN. The comparison was based the Equal Error Rate (EER), False Rejection Rate (FRR), False Match Rate (FMR), and True Match Rate (TMR). Results show that the proposed algorithm outperformed the others in maintaining a lowest EER, FMR, FRR and highest TMR.
},
year = {2024}
}
TY - JOUR T1 - Speaker Recognition System Using Hybrid of MFCC and RCNN with HCO Algorithm Optimization AU - Stephen Nyakuti Otenyi AU - Livingstone Ngoo AU - Henry Kiragu Y1 - 2024/10/10 PY - 2024 N1 - https://doi.org/10.11648/j.ijiis.20241305.11 DO - 10.11648/j.ijiis.20241305.11 T2 - International Journal of Intelligent Information Systems JF - International Journal of Intelligent Information Systems JO - International Journal of Intelligent Information Systems SP - 94 EP - 108 PB - Science Publishing Group SN - 2328-7683 UR - https://doi.org/10.11648/j.ijiis.20241305.11 AB - Though there are advancements in speaker recognition technology, available systems often fail to correctly recognize speakers especially in noisy environments. The use of Mel-frequency cepstral coefficients (MFCC) has been improved using Convolutional Neural Networks (CNN) yet difficulties in achieving high accuracies still exists. Hybrid algorithms combining MFCC and Region-based Convolutional Neural Networks (RCNN) have been found to be promising. In this research features from speech signals were extracted for speaker recognition, to denoise the signals, design and develop a DFT-based denoising system using spectrum subtraction and to develop a speaker recognition method for the Verbatim Transcription using MFCC. The DFT was used to transform the sampled audio signal waveform into a frequency-domain signal. RCNN was used to model the characteristics of speakers based on their voice samples, and to classify them into different categories or identities. The novelty of the research was that it used MFCC integrated with RCNN and optimized with Host-Cuckoo Optimization (HCO) algorithm. HCO algorithm is capable of further weight optimization through the process of generating fit cuckoos for best weights. It also captured the temporal dependencies and long-term information. The system was tested and validated on audio recordings from different personalities from the National Assembly of Kenya. The results were compared with the actual identity of the speakers to confirm accuracy. The performance of the proposed approach was compared with two other existing speaker recognition the traditional approaches being MFCC-CNN and Linear Predictive Coefficients (LPC)-CNN. The comparison was based the Equal Error Rate (EER), False Rejection Rate (FRR), False Match Rate (FMR), and True Match Rate (TMR). Results show that the proposed algorithm outperformed the others in maintaining a lowest EER, FMR, FRR and highest TMR. VL - 13 IS - 5 ER -
Electrical and Telecommunication Engineering Department, Multimedia University of Kenya, Nairobi, Kenya
Biography: Stephen Nyakuti is a masters Student at the Multimedia University of Kenya undertaking Master Degree Course in Multimedia and Communication Engineering. He has degree in Telecommunication Engineering and Information Technology and Post Graduate Diploma in Mass Communication. He has Ten years of working experience in the Engineering and ICT fields.
Research Fields: Telecommunications, Communication, Information Technology

Electrical and Telecommunication Engineering Department, Multimedia University of Kenya, Nairobi, Kenya
Biography: Livingstone Ngoo: Prof. Dr-Eng. Livingstone M. H. Ngoo is a multifaceted professional with a distinguished career in electrical engineering, university administration, research, and education. Currently serving as the Acting Deputy Vice Chancellor for Academic Affairs, Research, and Innovation at Multimedia University of Kenya (MMU), Dr. Ngoo brings a wealth of experience and expertise to his role. Dr. Ngoo holds a Ph.D. in Electrical Power Systems, specializing in automation using fuzzy logic techniques and Master of Science Degree in (Control Engineering). His extensive experience encompasses designing, supervising, and commissioning electrical works and generators for diverse institutions.
Research Fields: Telecommunications, Control Engineering, Power Systems, Electrical and Electronics,

Electrical and Telecommunication Engineering Department, Multimedia University of Kenya, Nairobi, Kenya
Biography: Henry Kiragu has over twenty-five (25) years of teaching experience in the fields of Electronics and Telecommunication Engineering at undergraduate and graduate levels. He has supervised many research projects and theses for undergraduate as well as postgraduate level students in addition to publishing numerous papers in peer-reviewed journals and conference proceedings. Kiragu holds a Doctor of Philosophy (PhD) in Electrical and Electronics Engineering (2020) and a Master of Science (MSc) in Electrical and Electronics Engineering (2013) degrees from the University of Nairobi, Kenya. He is also a holder of a Bachelor of Technology (BTech) in Electrical and Communications Engineering degree (1994) from Moi University in Kenya. Currently, he works as a Senior Lecturer of Electronics and Telecommunication Engineering at the Multimedia University of Kenya. He is a member of the Engineers Board of Kenya (EBK) as well as the Institute Of Electrical and Electronics Engineers (IEEE).
Research Fields: Telecommunications, Electricals and Electronics

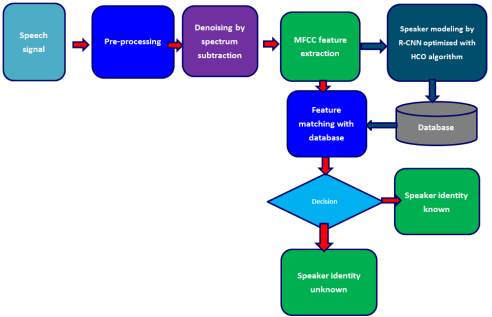
Figure 1. Proposed Speaker Recognition method.
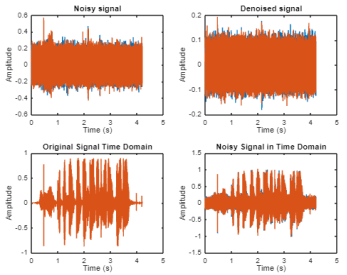
Figure 2. Original, noisy and denoised audio signals.
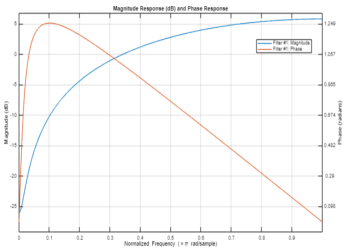
Figure 3. Magnitude and Phase response against normalized frequency.
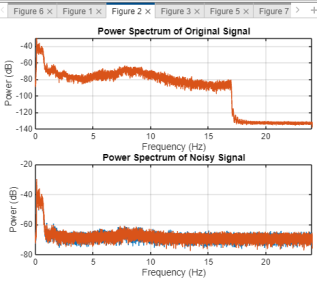
Figure 4. Power spectra of original and noisy signals.
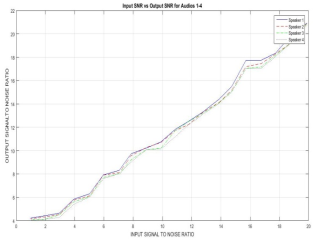
Figure 5. Input against Output Signal to Noise Ratio.
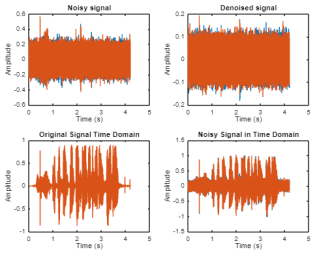
Figure 6. Pre-emphasized signal in frequency and time domains.
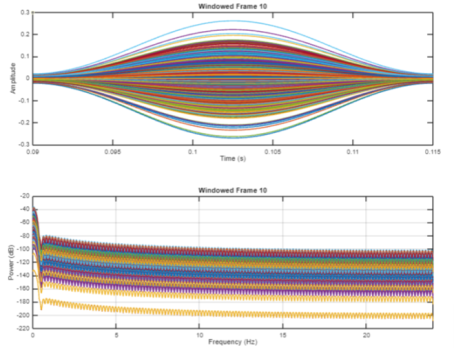
Figure 7. Windowed frames in time and frequency domains.
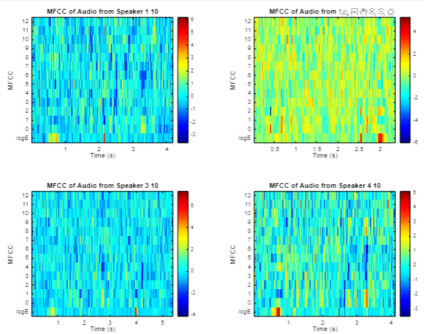
Figure 8. Mel filter bank response.
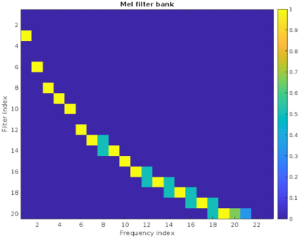
Figure 9. Mel filter bank.
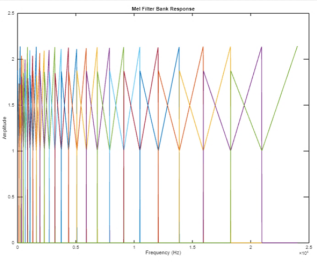
Figure 10. MFCC of four audio signals.
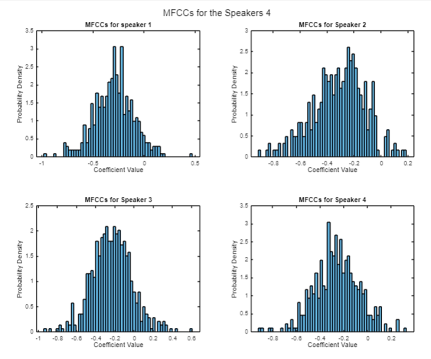
Figure 11. Histograms of the MFCCs for the four audios.
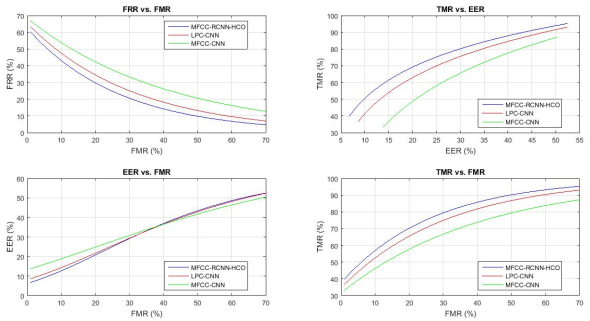
Figure 12. Performance indicators of the algorithms.

